Definição de um modelo XML para a base de dados que está sendo criada para a Biblioteca IME. Este modelo deverá ser usado para fazer a carga da nova base de dados, a partir da importação de dados de bases já existentes.
Este trabalho é um sub-projeto que integra o Projeto de Informatização da Biblioteca do IME. O sistema está dividido em módulos, minimizando a dependência entre os grupos de desenvolvimento do projeto.
|

A definição do modelo XML encaixa-se no Módulo Acervo.
Os dados do Acervo da Biblioteca encontram-se, no momento, em duas bases de dados:
Urge sistematizar o processo de importação de dados das bases existentes para a nova base que está sendo criada.
|






XML é uma linguagem de marcação, assim como HTML. Basicamente, o que diferencia estas duas linguagens é que a primeira foi criada para descrever dados, enquanto que a segunda foi criada para exibir dados.
XML permite que o desenvolvedor crie seus próprios marcadores (estruturas rotuladas tag), daí sua flexibilidade.
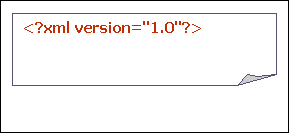
Há apenas uma primeira linha [ver fig. exemplo 1] que é obrigatória para que o documento seja validado: uma declaração XML que define a versão XML do documento em questão.
 |
| 3.2.1 | Elementos | |
Cada marcador define um elemento, que pode possuir elementos-filhos.
É uma estrutura em árvore: uma raiz com nós-filho.
| ||
| 3.2.2 | Atributos | |
|
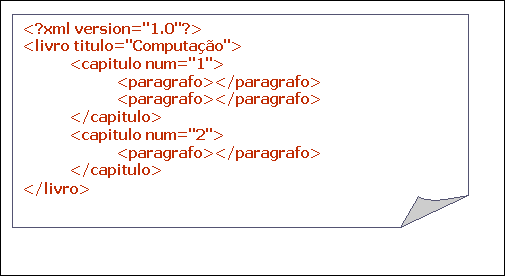
Elementos podem ter atributos associados a eles: uma informação adicional que não descreva uma estrutura. Não há uma regra que explicite quando um dado é um elemento ou um atributo, mas há desvantagens no uso desse último. No exemplo abaixo [FIG 3.2.2.a)], título não deveria ser definido como atributo do elemento livro. Note que título é uma estrutura que pode conter subtítulos. Atributos não são expansíveis e nem multi-valorados, e seu uso não é recomendado em vários casos. Ainda no exemplo abaixo, o número do capítulo é apenas uma informação extra sobre o elemento capítulo: neste caso, faz mais sentido o uso de um atributo.
|

|

Nosso documento XML descreve um ITEM DE ACERVO da Biblioteca do IME: um exemplar físico de alguma obra. De que forma as informações sobre um item do Acervo estão estruturadas? Não se trata, aqui, de saber quais as relações da base de dados. Antes, é a descrição de um ITEM DE ACERVO a partir de seus elementos (autores, assuntos relacionados, eventos associados, edições, etc), respeitando a hierarquia de registros.
| Etapa 1 | Gerar documentos XML (segundo o modelo definido) a partir da base-origem. |
| Etapa 2 | Fazer a carga da nova base de dados a partir dos arquivos .xml gerados. |
|
| |
O DTD é descrição estrutural do documento e inclui regras de interpretação para cada uma das informações contidas no mesmo. Ele contém a definição dos elementos e listas de atributos, a cardinalidade dos elementos, a hierarquia dos registros.
Por exemplo: ITEM DE ACERVO pode ser PERIÓDICO, NÃO-PERIÓDICO, MULTIMIDIA ou TESE. Cada um deles é um elemento distinto. Determinamos, também pelo DTD, que o item pode ter mais de um ASSUNTO associado, mas apenas uma EDITORA.
Suponha que o parser A gere um arquivo itemYYY.xml a partir de dados selecionados numa das bases-origem. Esse arquivo será um documento XML válido apenas se obedecer às definições DTD.
A metodologia utilizada foi:
No caso específico do parser A para a base do IDBIME, utilizamos a seguinte metodologia:
Esse último script - o parser A para o IDBME - foi desenvolvido em Java e requer driver para acesso ao servidor postgresql (note que a base-origem, neste momento, é uma cópia da base original do IDBME).
A metodologia utilizada foi:
Esta apresentação [.pdf] mostra como foi desenvolvido um leitor de arquivos XML (uma classe em Java) que, após analisar seu (do arquivo) contéudo, faz a carga da nova base de dados com as informações obtidas pelo parser.
| MARÇO / 2004 | |
| 1. | Primeiro contato com o projeto: conhecer o que já foi realizado e o que está sendo desenvolvido. |
| ABRIL / 2004 | |
| 2. | Estudo dos modelos conceitual, lógico e físico da nova base de dados. |
| 3. | Análise de dados do ID-BIME (sistema da Biblioteca a ser substituído). Entender os tipos de dados contidos na base de dados do ID-BIME. |
| MAIO / 2004 | |
| 4. | Análise de dados do ID-BIME. Extrair do ID-BIME o que está relacionado ao Acervo da Biblioteca. Identificar semelhanças e diferenças com o novo modelo. |
| 5. | Estudo dos módulos navegacional e operacional do novo sistema. |
| 6. | Estudo do novo modelo conceitual, apresentado pelo professor João Eduardo, para a nova base de dados. |
| JUNHO / 2004 | |
| 7. | Enumeração dos atributos que faltam nas novas relações. Cada integrante do grupo verifica, no modelo novo, se algo ainda não está modelado segundo as especificações de cada parte do sistema. |
| 8. | Análise do novo modelo gerado |
| JULHO / 2004 | |
| 9. | Assimilação do modelo da base de dados anterior da Biblioteca (gerar base em PostgreSQL a partir de uma base em Clipper) |
| 10. | Estudo de ferramentas: XML e Banco de Dados |
| AGOSTO / 2004 | |
| 12. | Desenho do novo modelo em XML |
| SETEMBRO / 2004 | |
| 13. | Desenvolver dois parsers: um para gerar o arquivo XML com os dados do IDBIME; outro para extrair do arquivo XML os dados para a carga da base nova. |
| OUTUBRO~NOVEMBRO/ 2004 | |
| 14. | Redefinição do modelo e ajuste nos scripts dos parsers. |
| DEZEMBRO/2004 ~ FEVEREIRO/2005 | |
| 15. | Carga da base de dados (em fase de homologação) |
| 1. C | Script de geração de uma base de dados em um servidor PostgreSQL [desenvolvido por Celina Maki Takemura] |
|
| |
| 2. Perl | Script de importação de dados de uma base Clipper para o servidor PostgreSQL |
|
| |
| 3. XML | |
|
| |
| 4. Java | |
|
| |
| 5. Banco de Dados | |
|
| |
O estudo do XML mostrou as várias possibilidades do uso da linguagem de marcação para a descrição de dados.
A existência de APIs para XML (disponíveis em outras linguagens de programação além de Java) reflete as facilidades do uso do XML.
WALL, L.; CHRISTIANSEN, T.; SCHWARTZ, R.L; POTTER, S. Programming Perl. California: O´Reilly & Associates, 1996.
HOLZNER, STEVEN.Inside XML. Indiana: New Riders, 2001.
http://perl.about.com/
http://www.activestate.com
http://www.cpan.org
http://search.cpan.org/~arc (Aaron Crane)
http://crazyinsomniac.perlmonk.org/perl/ppm
PostgreSQL 7.4.3 Documentation
http://www.xml.org
Papers about XML (by Ronald Bourret)
XML Specification
Apache XML Project